
How we bring Domain Expertise to our GPT?


Overview
General purpose large language models like GPT4, Claude, Llama have ignited new possibilities for conversational AI. However, their full potential is unlocked when they can incorporate specialized knowledge about topics they are conversing on.
In our case, we wanted to build an AI assistant specialized in carbon markets - a complex industry filled with fragmented data and niche expertise. Most of this knowledge lives trapped in pdf reports and unstructured content across the web.
That's where leveraging additional LLM capabilities becomes critical. With the right context and content injection, we can create LLMs that go beyond mere conversations to provide meaningful analysis and recommendations.
A note on OpenAI GPTs
Released at the November 2023 DevDays keynote, GPTs have redefined the landscape of AI chatbots, offering a new paradigm for building domain-specific assistants. One can enhance ChatGPT with custom instructions and external actions, enabling the model to behave in unique ways tailored to specific domains.
GPT in Action
GPT Demo
Building a Domain Expert GPT
We set out to build a custom GPT powered by carbon market data and documents. One of the first requirements was to automatically aggregate relevant content from this niche industry. Ethical web scraping was the first obvious solution. However, building and managing scrapers from scratch can be complex. That's where we use Apify. Apify is a web scraping and automation platform that makes harvesting web data easy.
Disclosure: This article is not sponsored or influenced in any way by OpenAI, Apify or any other third-party entity referenced. All opinions expressed here are based solely on our own independent experiences. We have no financial affiliations with any vendor mentioned that could introduce bias. This is non-promotional content aimed purely at knowledge sharing around building specialist AI assistants.
RAG Pipeline
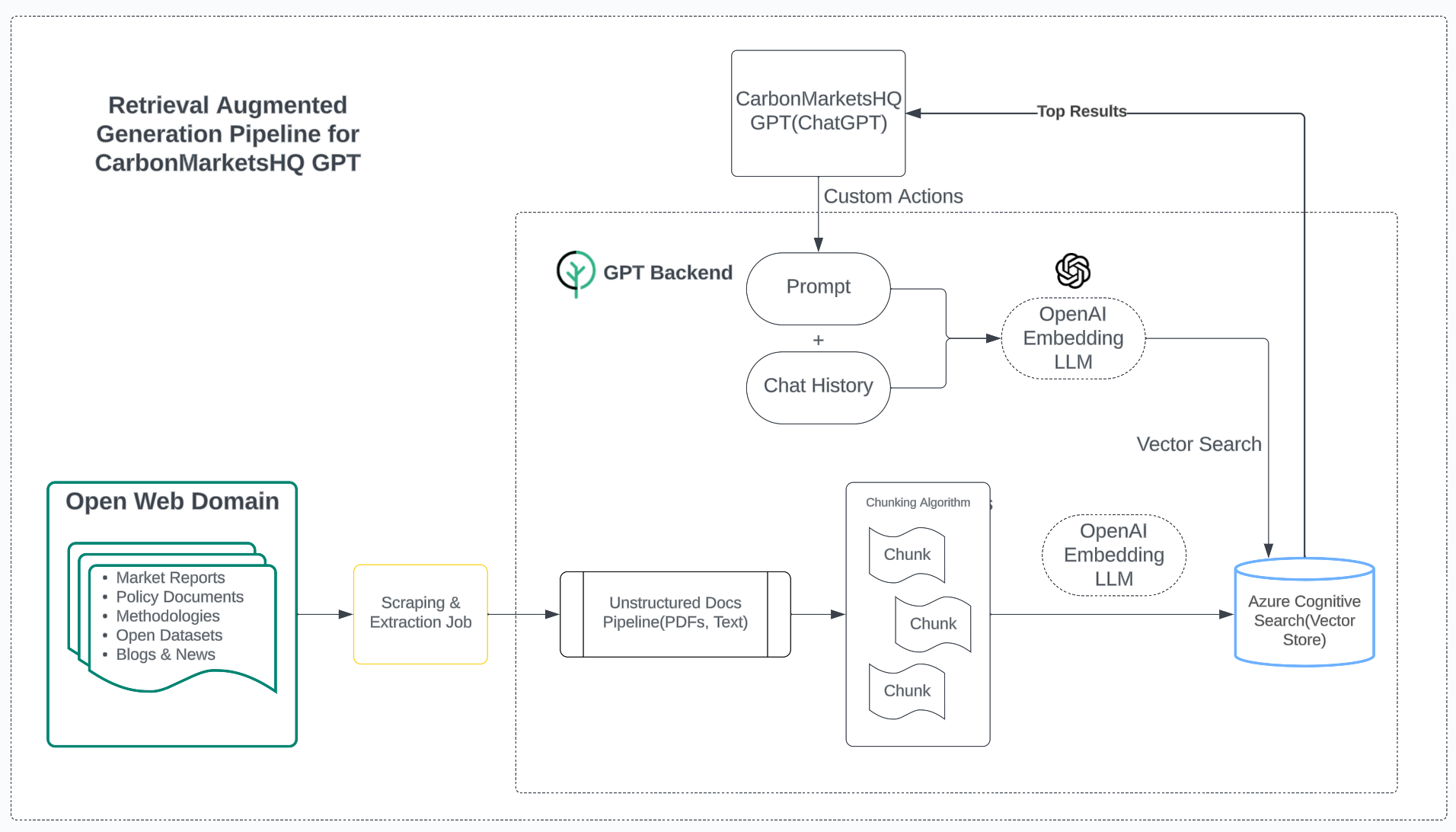
Our asynchronous indexing service triggers crawlers with seed urls to scrape knowledge bases, blogs and download available pdfs from websites in our corpus. This unstructured data is chunked, embeddings are created to be indexed into Azure cognitive search.
We then periodically run embeddings generation over data scraped in an Azure storage. Finally, we expose our database as bunch of domain relevant APIs and integrate them using custom actions provided by ChatGPT. This is the infrastructure that powers lightning fast hybrid(keyword + vector) semantic search behind every query to our GPT.
While we have built core capabilities, our journey of enhancing our GPT is just getting started. Here are some areas we are working on-
Expanding Knowledge Corpus
We're working on integrating more datasets- like Global Stocktake, IPCC Reports, NDC Registries, CDR data etc. If you'd like us to ingest more datasets for your usecase, please reach out at [email protected].
Quoting References
Quoting references and giving credits for the content is crucial, we're working on making sure our GPT accurately quotes where it is querying the data from.
Improving Semantic Search
A simple vector search only goes so far. We're continuously improving page chunking algorithms and plan to integrate LLM chaining behind the scenes to improve the answers.
Fine Tuning
As we continue ingesting new sources, our goal is to rapidly grow the knowledge corpus to go beyond RAG and train our own LLM.
Before you go
We warmly invite you to join our early access list. By subscribing to our updates, you will be amongst the first to experience our feature launches. You can also write to us for feature requests, feedback or reporting any issues with the platform.